

Hallo zusammen,
in meinem heutigen Blog-Eintrag möchte ich auf das Thema Nutzung von Sprachmodellen in unserem Produkt Jadice Flow (kurz auch “Flow”) eingehen. Es handelt sich bei Flow ja vereinfacht gesagt um einen modularen Hintergrundservice, der verschiedene Aufgaben wie z.B. Bildkonvertierung durchführen kann. In Form von Workern können modular weitere Funktionen hinzugefügt werden.
Künstliche Intelligenz und Large Language Sprachmodelle sind nicht zuletzt durch das von OpenAI entwickelte ChatGPT aktuell in aller Munde.
Auch in unseren Produkten evaluieren wir hier die Möglichkeiten und Präzision der Modelle, um z.B. in Flow Worker anzubieten, um LLM Modelle z.B. lokal oder via OpenAPI Anbindung zu nutzen.
In diesem eher technischen Blog Eintrag möchte ich kurz auf das Thema Retrieval Augmented Generation (RAG) im Bereich der Text Generierung eingehen, in dem wir zuletzt Experimente durchgeführt haben.
Es gibt auch am Ende ein kleines Mini-Selbstmach-Tutorial, um solche Funktionen auch lokal einfach ausprobieren zu können. Oder für die, die das nicht selber tun wollen – Screenshots.
Retrieval Augmented Generation
Kommen wir zunächst zur Begriffsklärung. Der Begriff Retrieval Augmented Generation (RAG) beschreibt einfach gesagt, dass dem Sprachmodell bei der Ausführung einer Benutzerabfrage weitere Dokumente oder Informationen zusätzlich übergeben werden.
Diese Zusatz Information (“Context”) wird dann für eine genauere Antwort verwendet. So kann das Modell genauere Antworten liefern, auch ohne spezielles Fein-Tuning.
Ablauf
Hier ist zu erkennen, die Benutzerabfrage (“Question” links oben) einerseits an das Sprachmodell übergeben wird. Andererseits wird auf Basis der Abfrage der Context mit relevanten Informationen aus der Wissensquelle befüllt, hier aus einer Vector Datenbank.
Aus dem englischen Wikipedia Artikel:
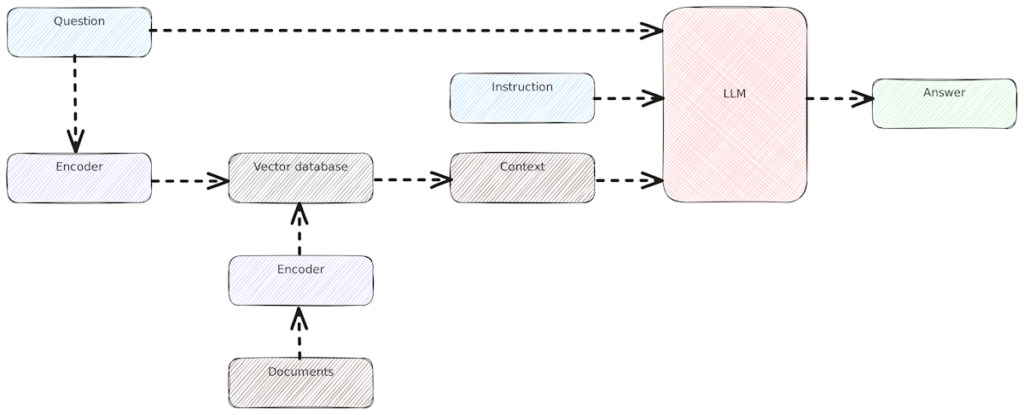
Diesen Ablauf wollen wir uns zunutze machen, um einem Sprachmodell Zusatzinformationen, z.B. aus dem zu verarbeitenden Dokument bereitzustellen.
Token Beschränkung
Bei einer zunehmenden Anzahl an Hintergrundinformation können natürlich nicht immer alle an das Modell übergeben werden.
Dies kann eine zunehmend schwierige Aufgabe sein, dem Modell die passenden Informationen bereitzustellen. Hier kommen dann eben Indizierungs-Mechanismen und die Vector DB zum Einsatz, die Informationen zu Stichwörtern schnell liefern kann.
Eine Kennzahl dabei ist die Token-Anzahl. Ein Token ist hier quasi ein Wort bzw oft vorkommendes Zeichen-Muster.
Die Sprachmodelle unterstützen ggf unterschiedlich viele Input-Tokens. Kleinere Modelle sind oft auf 5k-8k Tokens beschränkt, z.B. die gängigen/kleineren “Lama3” und “Mistral”-Modelle.
Es gibt von diesen Modellen aber auch spezielle Varianten, die einen Kontext von bis zu 128k Tokens unterstützen (z.B. das yarn-mistral Modell). Das entspricht dann quasi schon einem >250 Seiten Buch.
Hier hatten wir bisher nur deutlich kleinere Inhalte mit 1-5k Tokens im Wissens-Bereich. Bleibt also noch Spielraum für weitere Quellen und Experimente.
Anwendungsmöglichkeiten
Mit diesem Hintergrundwissen ausgestattet, haben wir dann verschiedene Experimente durchgeführt. Eines davon ist der Flow worker-gpt der im folgenden Abschnitt etwas erläutert wird.
Grundidee ist hier, dass das in Verarbeitung befindliche Dokument als RAG-Quelle verwendet wird, um Klassifizierungen bzw Fragen zum Dokument zu ermöglichen.
Jadice Flow
Unsere Jadice Flow Worker sind zumeist Spring Boot Applikationen. Für einen ersten Test bot sich hier also Spring AI an, welches bereits einige Adapter mitbringt.
Es gibt natürlich auch weitere Möglichkeiten, LLMs auszuführen. So nutzen andere Flow Worker z.B. auch direkt Python Bibliotheken.
Der (noch experimentelle) worker-gpt nutzt hierbei also die zu verarbeitenden Dokumente als RAG Quelle. Es können Text oder Bildquellen genutzt werden.
Im Falle von Bildern können z.B. Fragen wie
"is this a document or receipt?", oder
"is there a red stamp on the image?"
gestellt werden.
Die Qualität der Antworten ist dabei noch ein kritischer Punkt, der durch entsprechende Vorverarbeitung ggf. weiter optimiert werden kann (z.B. das Bild in optimales Erkennungsformat konvertieren vor der Klassifizierung; ähnlich wie bei OCR).
Ebenso spielt das verwendete Modell eine Rolle bei der Erkennung. Diese gibt es meist in unterschiedlichen Quantisierungsgrößen – je nach verfügbarer Hardware sind dann kleinere oder größere Modelle verwendbar.
Unsere ersten Tests haben wir mit einer lokalen Ollama Installation durchgeführt (dazu später mehr). Alternativ kann via SpringAI auch die OpenAI API direkt angesprochen werden (mit entsprechendem API Key).
Ausreichende Qualität der Antworten vorausgesetzt, wäre dann auch eine Steuerung des Job-Ablaufs anhand der erkannten Kriterien möglich. Z.B. Dokumente mit rotem Stempel bei der Verarbeitung speziell behandeln.
Dieses Thema steckt Aktuell noch in einer experimentellen Phase und wird in der nächsten Zeit weiter beleuchtet.
Chatbot für das Unternehmen
Ein weiterer Anwendungsbereich ist z.B. ein Chatbot, um Fragen zur Organisation oder anderen betrieblichen Dingen schnell stellen zu können.
Ebenso ist dies als Frage-Werkzeug für Kunden denkbar, wenn z.B. der lokale Chatbot mit der Dokumentation verknüpft wird.
Beispiel mit Ollama und Open Web UI
Eine einfache Form eines solchen Chatbots kann man mit relativ geringem Aufwand auch lokal einrichten.
Dies ist der praktische Teil dieses Blogs – wer dies nicht selbst einrichten möchte, kann diesen Abschnitt auch schnell überfliegen und direkt zu den Screenshots übergehen.
Im Folgenden richten wir einen lokalen Ollama mit der Standard UI ein, um eine Chat Abfrage mit RAG sowie Bildabfrage durchzuführen.
—–
Eine Option zur einfachen lokalen Ausführung von LLMs ist Ollama.
Dieser Server kann extern laufen, oder auch innerhalb eines Worker Containers. Damit können “Text -> Text” Modelle oder auch Multi-Modale Modelle (“Image+Text -> Text”) ausgeführt werden. Für einige Aufgaben der Bild / Audioerzeugung ist Ollama aktuell jedoch nicht geeignet – dort sind meist direkt Python Libraries im Einsatz.
In diesem Beispiel installieren wir den Ollama Server und die Open Web UI (früher auch Ollama UI genannt) via Docker.
Installation via Docker
docker-compose.yaml (zum erweitern klicken)
networks:
ollama-network:
driver: bridge
services:
# Ollama
ollama:
volumes:
- ../_Volumes/Ollama:/root/.ollama
container_name: ollama
tty: true
restart: unless-stopped
image: ollama/ollama:latest
# GPU support
deploy:
resources:
reservations:
devices:
- driver: ${OLLAMA_GPU_DRIVER-nvidia}
count: all
capabilities:
- gpu
ports:
- 11434:11434
networks:
- ollama-network
# WebUI
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
volumes:
- ../_Volumes/open-webui:/app/backend/data
depends_on:
- ollama
ports:
- 4242:8080
environment:
- OLLAMA_BASE_URL=http://ollama:11434
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stopped
networks:
- ollama-network
Die Pfade der Volumes sind ggf zu kontrollieren und anzupassen.
In diesem Beispiel geben wir dem Container die NVIDIA GPU; AMD Karten werden prinzipiell unterstützt sind aber von mir ungetestet.
Theoretisch läuft Ollama auch ohne GPU komplett auf CPU, dann ist allerdings die Performance für einen Echt-Betrieb nicht wirklich gut nutzbar (Minuten statt Sekunden für Abfragen).
Web UI
Unter http://localhost:4242/ sollte nun die WebUI verfügbar sein. Evtl ist ein Initialer User anzulegen.
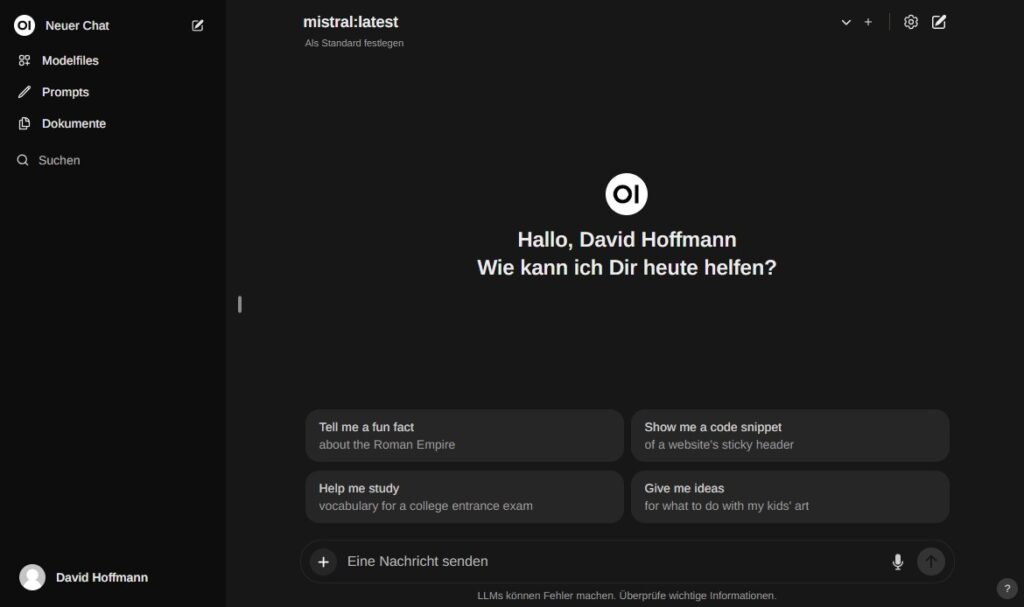
Modelle prüfen
Man sollte nun zunächst die installierten Modelle prüfen. Rechts oben zunächst die Einstellungen öffnen, dann kann ein Modell von Ollama.com abgerufen werden.
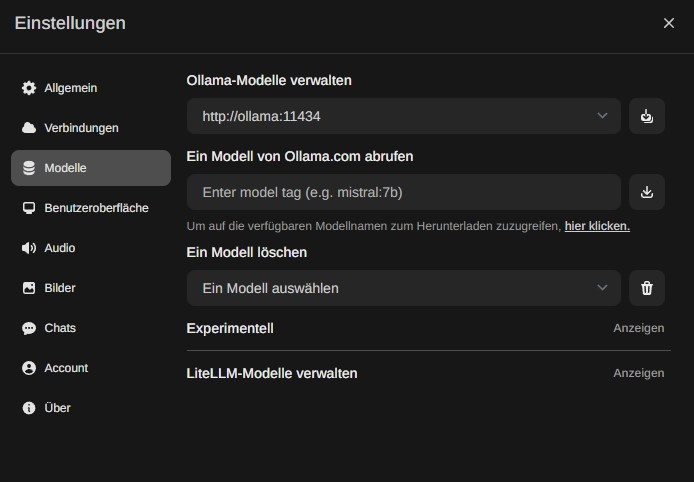
Chat-Modelle für Text-Fragen sind z.B: “llama3” (empfohlen) oder “mistral”. Üblicherweise werden ohne Tag-Angabe dann die 7B-Modelle verwendet, die ca 4gb groß sind.
Mit Angabe eines Tags kann auch eine andere Variante geladen werden, z.B. “llava:13b” (die nächst größere verfügbare).
Für Bild-Fragen wird das “llava” Modell verwendet. Dieses bei Bedarf ebenfalls abrufen. Dort ist die 13b-Variante auch sehr empfehlenswert, benötigt aber viel RAM.
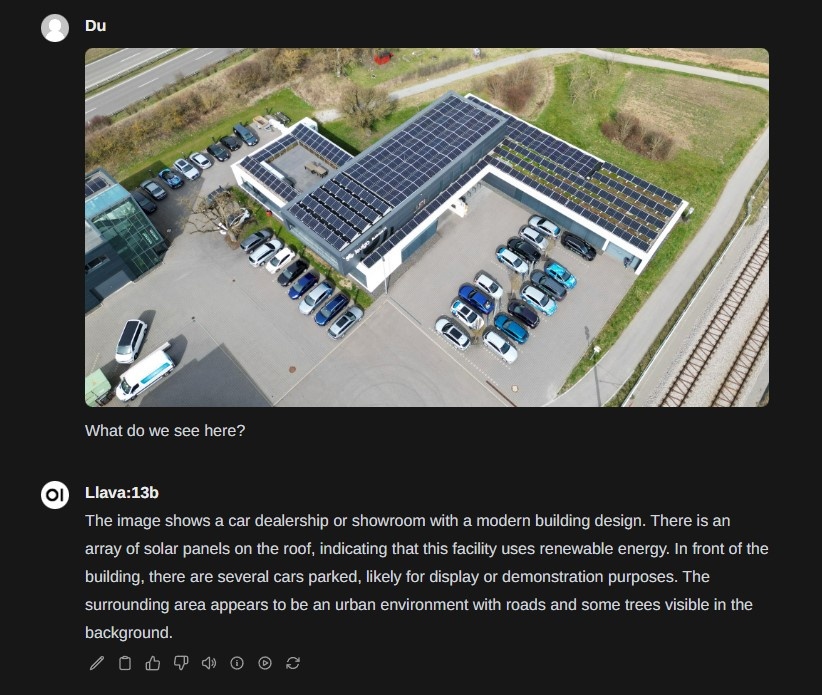
Beispiel Bildabfrage
Dateien/Bilder können über das (+)-Symbol im Chat hinzugefügt werden.
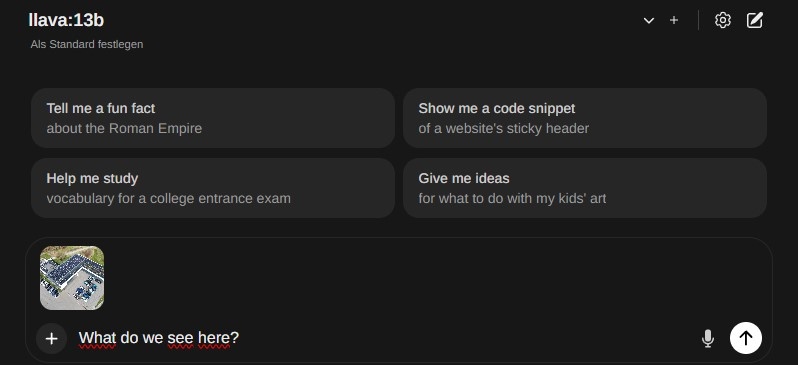
Wichtig: Oben das “llava” Modell auswählen.
Das Ergebnis beweist:
Levigo ist neuerdings auch ein Autohändler :-)
Beispiel Chat mit RAG
Nun zum finalen Teil: Chat-Abfrage mit RAG.
Hierzu kann man links im Hauptmenü “Dokumente” auswählen und dann im rechten Bereich via (+) hochladen.
Ich habe zu Testzwecken Teile aus der Jadice Flow Dokumentation in mehrere .txt-Dateien verpackt und mit dem Hashtag “jadice flow” versehen.
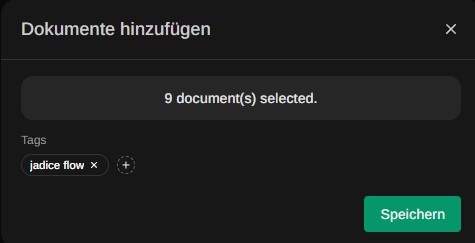
In der OpenWebUI können Wissensquellen bei der Abfrage über ein Hashtag (#) referenziert werden. Ebenso sind URLs zu Webseiten möglich. Aber hier genügt zunächst also #jadice flow
Diese Frage könnte ohne die Wissensquelle nicht präzise beantwortet werden. Aber in unserem Fall stimmt es nun zu 100%:

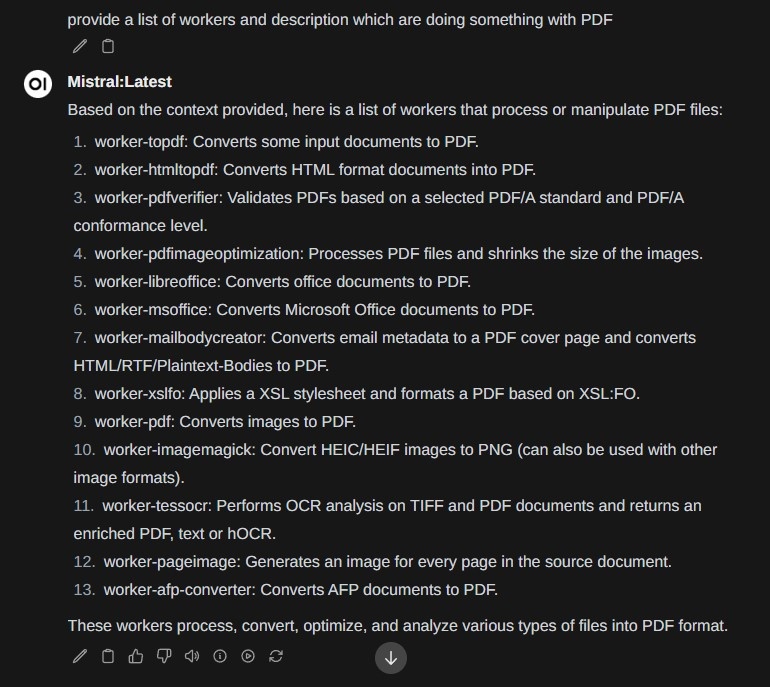
Ebenso sind andere Detailfragen möglich, z.B. nur die Worker aufzählen, die mit PDF zu tun haben (hier fast 100% korrekt, Nummer 9 ist eigentlich identisch zu Nummer 1. Die vollständige Liste in der Dokumentation sind ca 30-40 Worker):
Oder die Frage nach Code-Beispiel, wie man einen Job in Flow starten kann (die Richtung stimmt):
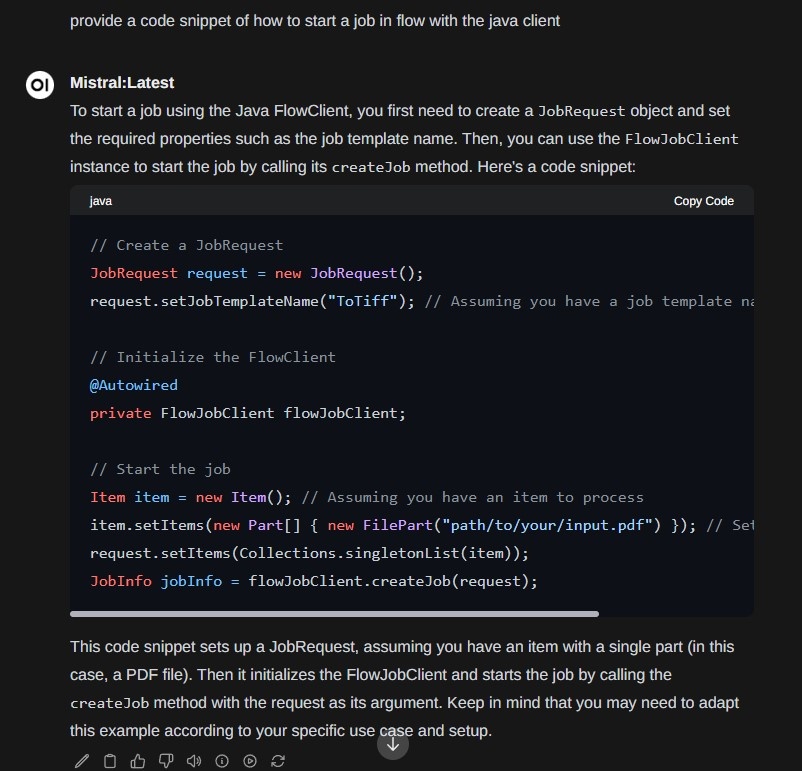
Dieses Prinzip ist auch insbesondere für Leute interessant, die eine Markdown / Text Wissenssammlung z.B. mit Obsidian oder Zettlr angelegt haben. Im Unternehmensbereich ist dann noch eine Verbindung z.B. zum Ticketsystem oder weiteren Quellen sinnvoll.
Just one more thing: Übersetzung
Natürlich wollte ich auch wissen, wie sich die LLM basierten Übersetzungsmodelle schlagen.
Dieses Thema ist auch insofern interessant, da Sprachmodelle oft vorrangig mit englischen Texten trainiert werden. In manchen Fällen können bessere Ergebnisse erzielt werden, wenn die Benutzereingabe (oder Wissensquelle) vorher übersetzt wird. Allerdings kostet dieser Vorgang natürlich auch Zeit und muss im Gesamtprozess eingeplant werden.
Vorbereitung
Dafür wird ein eigenes Modell benötigt. Die Standardmodelle aus der Ollama Library können dies nur bedingt gut. Man kann aber eigene Modelle erstellen aus dem GGUF Modell-Format. (z.B. von huggingface.co).
Ich habe also die freie GGUF-Version des ALMA:13b Modells in Ollama importiert und dort verfügbar gemacht. Es kann nun via einfachem pull gezogen werden (ist allerdings groß – ~8gb).
Wie bei den anderen Modellen über die GUI das Modell ziehen:
winkefinger/alma-13b (“Winkefinger” ist mein Pseudonym/Namespace dort)
Alternativ via Kommandozeile im Container (ollama pull ...)
Details siehe auf der Ollama Seite für alma-13b bzw den darin enthaltenen Links zu den Original-Modellen.
Anwendung
Man benötigt folgende Art Eingabe:
Translate thisfrom German to English:German: [prompt]English: |
Beispiel:
Die offiziellen Übersetzungsrichtungen dieses Modells sind:
English ↔ German, English ↔ Czech, English ↔ Icelandic, English ↔ Chinese, English ↔ Russian
Daher ist es ok, dass hier bei Deutsch zu Chinesisch aus dem “Gurkensalat” ein “Tomatensalat” wurde (laut Google Translate). Aber vielleicht haben chinesische Pferde auch einfach nur andere Vorlieben… ;-)
Ebenso scheint das Modell auch grundlegend Französisch, Spanisch, Italienisch etc zu beherrschen.
Fazit
Die Möglichkeiten von RAG und Sprachmodellen sind vielfältig. Viele Frameworks stecken noch in den Kinderschuhen. Aber auch jetzt sind schon überraschende Ergebnisse möglich.
Es gibt mittlerweile natürlich auch eine Reihe weiterer generativer Anwendungsfälle. In den Bereichen Bild-/Animation oder Audioverarbeitung sind die verblüffenden Ergebnisse dann aber oft auch einhergehend mit rechtlichen Fragen zum verwendeten Trainings-Datensatz und Copyright-Fragen. Das ist ein Thema für einen weiteren Blog Post.
Im Bereich Jadice Flow sind vor allem Modelle interessant, um bestehende Bilder oder Text zu verarbeiten.
Text-Zusammenfassung ist bereits mit unseren bestehenden Workern ohne die bekannten Chat-Modelle möglich (dafür sind deterministischere NLP Modelle im Einsatz), aber künftig kommen noch weitere Themen wie z.B. verbesserte Schwärzungen / Anonymisierung dazu. Und beim Thema RAG sind wie erläutert Klassifizierungen und Fragen zum Dokument denkbar (z.B. ob ein Dokument sich an eine bestimmte Compliance-Regel bzw bestimmten Aufbau hält).
Zum Thema generative AI wird es auch bald schon weitere Posts geben.
Wer es bis hier her geschafft hat – danke fürs Durchhalten, beim nächsten Mal schaffe ich es evtl etwas kürzer. Und falls nicht, wisst ihr nun wenigstens, wie ihr den Text mit Ollama dann befragen könnt – war alles nur Vorbereitung… ;-)
Danke für die Aufmerksamkeit und bis zum nächsten Mal!