

Ein Ausblick aus dem levigo Labor:
Mit der Idee, dass bei unseren Produkten “Intent” der Antreiber ist, also die Überlegung, welchen Kundennutzen, wir erzeugen können, ergeben sich ganz neue Möglichkeiten Produkte zu steuern.
Dieser Artikel geht darauf ein, wie mit diesem Ansatz das automatische Anlegen von Verarbeitungsjobs sehr vereinfacht und verbessert werden kann, ohne dass man sich deswegen tief in die Technik einarbeiten muss.
Ebenfalls werden, sobald technisch weiterentwickelte Verarbeitungsschritte im System enthalten sind, automatisch neue Verarbeitungsstrategien ermittelt.
Die Idee einer intent-Steuerung bei jadice flow besteht darin, die Notwendigkeit zu fundiertem technischem Wissen bei der Erstellung von (neuen) Workflows zur Dokumentenaufwertung bzw. -verarbeitung zu reduzieren und im Idealfall ganz zu entfernen.
Stattdessen sollen Nutzer aus einer Selektion von fachlichen Anforderungen wählen können, diese bei Bedarf durch weitere Parameter anpassen und Dokumente darauf basierend Großteils automatisch verarbeiten. Nutzer müssen dabei nicht wissen, welche technische Bedeutung die gewählten Anforderungen haben und auch verschiedene Eingangsdokumententypen fordern keine zusätzliche Anpassung.
jadice intent greift auf eine Microservice Architektur (jadice flow) zurück, in welcher einzelne Services (Worker) einzelne Funktionalitäten ausführen.
Werden weitere Worker in das System hinzugefügt, Worker angepasst oder entfernt, reagiert jadice intent dynamisch und kann ohne Änderungne an der Verarbeitungslogik neue, den aktuellen Workern entsprechende, Pfade generieren. Wie die Worker, sind auch die definierten Anforderungen, Möglichkeiten zur Optimierung, Eingangsdokumentenformate und zusätzliche optionale Parameter zur Verarbeitung beliebig erweiterbar.
Dieser Blogpost soll einen Einblick in die Architektur und Funktionsweise von jadice intent bieten und erklären, wie die Überführung der Dokumentenaufwertung von einer technischen in eine anforderungsbezogene Ebene umgesetzt wird.
Architektur:
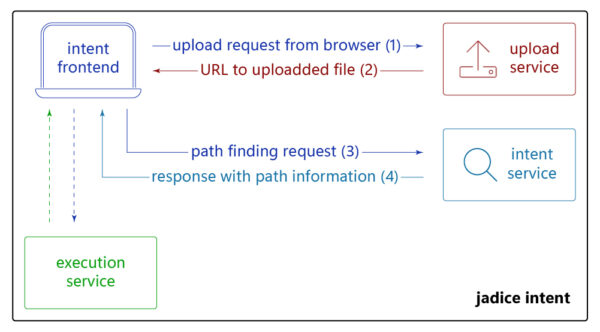
Die Dokumentenverarbeitung mit beginnt im Frontend mit der Auswahl einer zu verarbeitenden Datei und einer zu erreichenden Anforderung. Optional können einige Anforderungen um Anforderungsdetails erweitert werden, eine Pfadoptimierung angegeben und weitere Parameter optional gesetzt werden. Um die Verarbeitung für Benutzer noch weiter zu vereinfachen, gibt es auch die Möglichkeit mehrere Intents auf einmal zu wählen, um mehrfache Ausführung zu vermeiden.
Nach dem Klicken des Verarbeitungsbuttons wird eine Anfrage an einen Upload Service geschickt, welcher das angegebene Dokument in einen Speicher lädt, der für die zur Verarbeitung verwendeten Worker zugreifbar ist. Als Rückgabe erhält das Frontend eine URL zu der hochgeladenen Ressource, welche dann direkt mit den zur Verarbeitung spezifizierten Daten zum Aufruf des jadice intent Services verwendet wird.
Im intent Service wird zunächst mittels eines Analyzers der verwendete Dokumententyp analysiert. Basierend auf dem Ergebnis dieser Analyse und den anderen bereitgestellten Informationen sucht der Service alle möglichen Pfade zum Erreichen der Anforderung und ermittelt aus diesen basierend auf der spezifizierten Optimierung den besten Verarbeitungsweg.
Nach der Ermittlung des finalen Pfades wird ein Workflow Template erstellt, das direkt in jadice flow für die konkrete Verarbeitung verwendet werden kann. Im letzten Schritt erstellt der Service ein Rückgabeobjekt und übermittelt die Daten an das Frontend.
Dort können dann Informationen zum ermittelten Pfad angezeigt werden, das Workflow Template heruntergeladen werden, um es für gleichartige Dokumente für eine Massendatenverarbeitung verwenden zu können und auch direkt die Verarbeitung via jadice flow durchgeführt werden.
Verarbeitung:
Das Herzstück dieser Komponente ist die Pfadfindung. Startpunkt eines Pfades ist ein unverarbeitetes Dokument und das Ziel eine erreichte Anforderung.
Der Pfad wird dynamisch basierend auf der spezifizierten Anforderung, dem Eingangsdokumententyp und weiteren Parametern ermittelt. Hier ist es wichtig zu erwähnen, dass Verarbeitung und Pfadfindung strikt voneinander getrennt sind. Es wird also nicht direkt ein Pfad von einem Eingangsdokumententyp zu einer erfüllten Anforderung gesucht. Stattdessen wird hier eine Abstraktionsebene eingeführt und ein Pfad von einem Zustand, der das initiale Dokumentenformat repräsentiert, zu einem Zustand, der eine erfüllte Anforderung repräsentiert, gesucht.
Umgesetzt wird diese Funktionalität im Kern durch eine Zuweisung von Tags zu den verschiedenen im Netz verfügbaren Komponenten. Der Zustand der Durchsuchung wird initial basierend auf dem analysierten Eingangsdokumententyp gesetzt und gegebenenfalls um Implikationen des Typen erweitert – so wird bei einem Textdokument auch immer direkt angegeben, dass es schon im Initialzustand eine Textlayer gibt. Der Status ändert sich im Verlauf der Pfadsuche ständig und wird verwendet, um zu bestimmen, ob die gesuchte Anforderung gefunden wurde.
Die Anforderung wird ebenfalls mit Tags versehen, die diese fachlich beschreiben. Soll nur von einem Dokumententyp in einen anderen konvertiert werden, so könnte eine Anforderung beispielsweise nur aus einem Tag ‘type’ und einem entsprechenden Wert bestehen.
Bespiel:
Ein eingehendes Dokument soll nach PDF/A verarbeitet werden.
Je nach Anforderung kann Geschwindigkeit der Verarbeitung, Qualität desErgebnisses, Kosten der Verarbeitung oder die Größe der Zieldatei das wichtiges Kriterium für die Konvertierung sein.
Sollten neue Module bei jadice Flow zur Verfügung stehen, die neue Verarbeitungsstrategien ermöglichen, werden diese automatisch erkannt und die Verarbeitungslogik angepasst. Ohne eine Zeile Code schreiben zu müssen.
Auch wenn neue Worker aufgenommen werden, mit der neue Verarbeitungen ermöglicht werden, steht dieses Plug and Play zur Verfügung.
Abschließend hat jeder Worker zwei Sammlungen an Tags. Eine Sammlung zum Beschreiben, welche Voraussetzungen ein Status erfüllen muss, damit aus diesem ein Worker aufgerufen werden kann und eine Sammlung um zu beschreiben, welche Änderungen ein Worker an einem Status vornimmt.
Bei all diesen Tag-Zuweisungen wird akribisch darauf geachtet, dass die Summe aller verwendeten Tags genau die Funktionalität oder die Zustände der einzelnen Elemente repräsentiert. Nur so ist es möglich, dass nach der abstrakten Pfadfindung auch eine fehlerfreie Verarbeitung möglich ist.
Wird ein Pfad gefunden, wird dieser zu einer Liste an Pfaden hinzugefügt, welche nach Abschluss der Suche nach einem definierten Kriterium optimiert wird.
Die Durchsuchungslogik betrachtet die von bestimmten Zuständen aus erreichbaren Worker und ‘durchläuft’ verschiedene Worker, bis die Anforderung erreicht wird. Hierbei muss besonders darauf geachtet werden, dass keine Schleifen erzeugt werden oder Worker mehrfach hintereinander aufgerufen werden, ohne einen Fortschritt in der Durchsuchung zu erzielen.
Beispiel Durchsuchung:
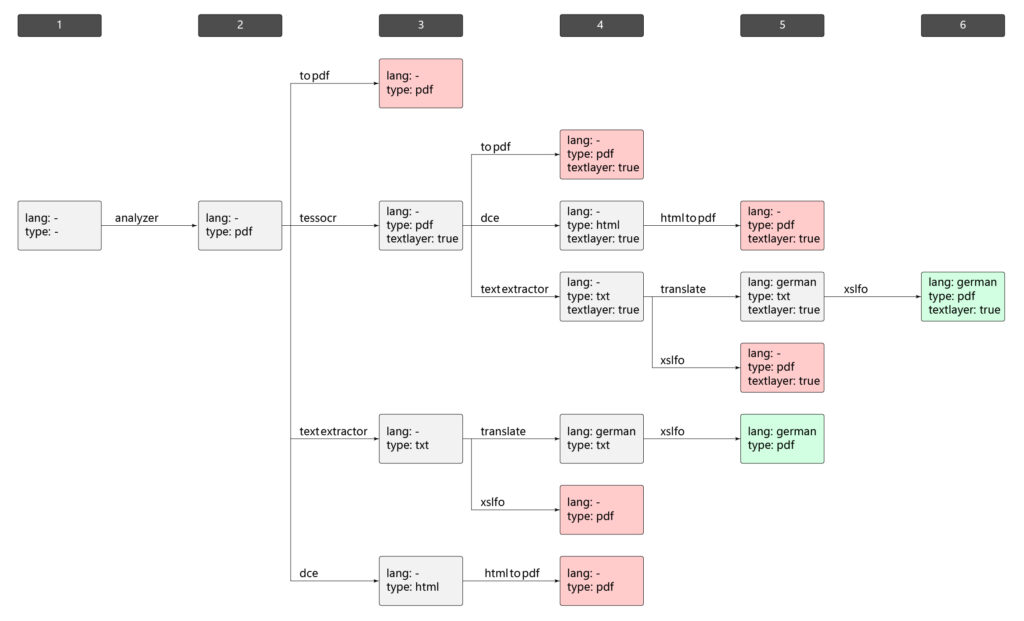
Zusätzlich zur reinen Durchsuchung gibt es Mechanismen, die Durchsuchung optimieren. So können beispielsweise Worker, basierend auf der gewählten Anforderung, aktiviert und deaktiviert werden.
Die Tag-Informationen zu Workern werden zentral mit allen anderen Informationen zu den Workern gespeichert, dadurch werden Inkonsistenzen zwischen Durchsuchung und Verarbeitung vermieden.
Da Worker eindeutige Verarbeitungstags benötigen, können diese nicht direkt parametrisiert werden, es wird also eine weitere Abstraktionsebene benötigt.
Jeder intent-Worker hat ein Set von grundlegenden Tags, welche zentral gespeichert werden. Für parametrisierte Versionen des Workers werden zusätzliche Tags gesetzt und für die ausführbaren Templates der Worker die entsprechend benötigten Parameter ermittelt.
Die konkreten Parameter werden hierbei nicht für die Suche benötigt, sondern erst nach der Bestimmung des konkreten Pfades zur Verarbeitung.
Vorteile
Durch diese Architektur für die Verarbeitung wird eine beliebige Erweiterung des Systems ermöglicht. Steht ein neuer Worker zur Verfügung, kann dieser einfach als intent Worker eingefügt werden. Neue Pfadsuchen werden diesen dann automatisch mit berücksichtigen und ggf. für die Verarbeitung verwenden.
Diese Technik bietet also sehr große Flexibilität in der Möglichkeit zur Verarbeitung. Das System ist nicht statisch, sondern kann, wenn neue Funktionalität verfügbar ist, beliebig erweitert werden. Der bedeutende Vorteil ist hierbei, dass Nutzer auf diese Neuerungen nicht aktiv reagieren müssen, da Neuerungen automatisch übernommen werden können. Zusätzlich können neue Anforderungen einfach definiert und zum System hinzugefügt werden.
Nutzer sind also von der technischen Spezifizierung befreit und können durch Dokumentenaufwertung und -verarbeitung mittels fachlicher Anforderungen durchführen.