

Hallo zusammen,
in meinem letzten Blog Post hatten wir ja bereits einen kleinen Ausflug in die Welt der generativen KI (genAI) gemacht. Dort hatten wir uns mit dem Thema Retrieval Augmented Generation (RAG) beschäftigt, und wie man bei Abfragen gegen generative Sprachmodelle Zusatzinformationen anreichern kann.
Manche der generativen KI Themen im medialen Bereich sind für jadice flow nicht unmittelbar relevant, dennoch will ich hier mal von ein paar Experimenten berichten, die ich in letzter Zeit durchgeführt habe.
Folgende Themen will ich “kurz” beleuchten:
- Video Animation via Stable Diffusion
- GenAI macht Musik
- Ausblick auf weitere Themen
Rechtliches
Ja, damit müssen wir jetzt mal anfangen…
Es scheint irgendwie bei allen Arten von generativen Modellen noch offene rechtliche Fragen zu geben. Oftmals geht es um das Thema Copyright bzw. wie und mit welchen Daten die Modelle trainiert wurden. Oftmals haben die Anbieter wohl einfach alles aus dem Netz abgesaugt, was verfügbar war.
Erschwerend kommt hinzu: Es können relativ einfach selbst feingetunte Modelle aus dem Basismodell abgeleitet werden. Bei solch abgeleiteten Modellen stellt sich (insbesondere für die Anwender) die Frage umso mehr, wenn diese dann auf den bekannten Plattformen veröffentlicht werden. Da wird man künftig vermutlich für mehr Transparenz sorgen müssen, um klarer aufzuzeigen, wie ein Modell trainiert wurde und was erlaubt ist.
Mittlerweile gibt es ja u.A. auch öffentlich verfügbare große Datensätze, die für das Training verwendet werden können (z.B. die vom LAION Projekt erstellten Datensätze; siehe auch dieser Blog Post).
Dennoch bleibt das Thema spannend – so hat OpenAI noch rechtlichen Spaß mit News-Anbietern, da dort einfach Daten für das Training verwendet wurden.
Stability.ai vom später näher erwähnten Stable Diffusion haben laufende Prozesse mit Giphy & Co (die auch selbst wiederum Klagen am Hals haben).
Und alle Anbieter bieten selbst wiederum aktuell bereits Produkte für Endkunden, um die Modelle “legal” und theoretisch kommerziell zu nutzen. Die neuen Versionen der Modelle werden aber zumindest mit besser geeigneten Datensätzen trainiert, als am Anfang.
Sehr spannend also, wie sich dieses Thema künftig entwickeln wird. Hier sind aktuell wohl viele Juristen dran, die sich mit dieser Materie besser auskennen und z.T. die Wege da auch erst noch beschreiten müssen.
Ich nutze z.B. bei Suno aktuell einen Pro-Account, um diese Probleme zu reduzieren.
Das wäre nun also alles vollkommen geklärt. Fangen wir also mal an, die Modelle intensiv zu nutzen – just for science….. ;-)
Stable Diffusion
Stable Diffusion (SD) ist mittlerweile eine Sprachfamilie von mehreren Modellen von stability.ai zur Bilderzeugung. Diese Modelle sind bereits seit einigen Jahren auf dem Markt und zuletzt ist mit Version 3 die neueste Modell Version erschienen.
Das Modell erlaubt durch Texteingaben, Bilder zu erzeugen.
Ähnliche Modelle in diesem Bereich sind z.B. Midjourney und Dall-E. Mit Gpt4-o ist auch im ChatGPT Bereich mittlerweile die Bilderzeugung möglich.
Das ist alles nicht wirklich neu und deswegen bin ich hier auch nicht in die Bilderzeugung eingestiegen, sondern direkt in die Animation :-)
Als Ziel wollte ich nun also eine Video Animation mit KI Mitteln erstellen.
Comfyui
Um mit SD Bilder erzeugen zu können, wird häufig eine Benutzeroberfläche verwendet. Anwenderfreundliche Variante ist die in diesem Bereich bekannte https://github.com/AUTOMATIC1111/stable-diffusion-webui . Dort können auch Animationen erzeugt werden, man hat aber auf den Ablauf der Verarbeitung weniger Einfluss. Z.B. mit dem Deforum-Plugin geht das Folgende auch, das aber nur nebenbei.
Aus dem jadice flow Bereich kommend, war der Ansatz der https://github.com/comfyanonymous/ComfyUI für mich persönlich aber näher liegend. In dieser UI können einzelne Schritte der Verarbeitung für die Bilderzeugung in Knoten dargestellt werden, die aneinandergereiht werden. Kam mir irgendwie bekannt vor ;-)
Ebenso sind hier weitere Knoten vorhanden, die meist mit der KI-Bildbearbeitung zu tun haben (z.B. für outpainting und inpainting, also Elemente aus dem Bild entfernen, verändern oder das Bild erweitern).
Hier z.B. mal ein kleiner Ablauf in ComfyUI, um ein Bild hoch zu skalieren:
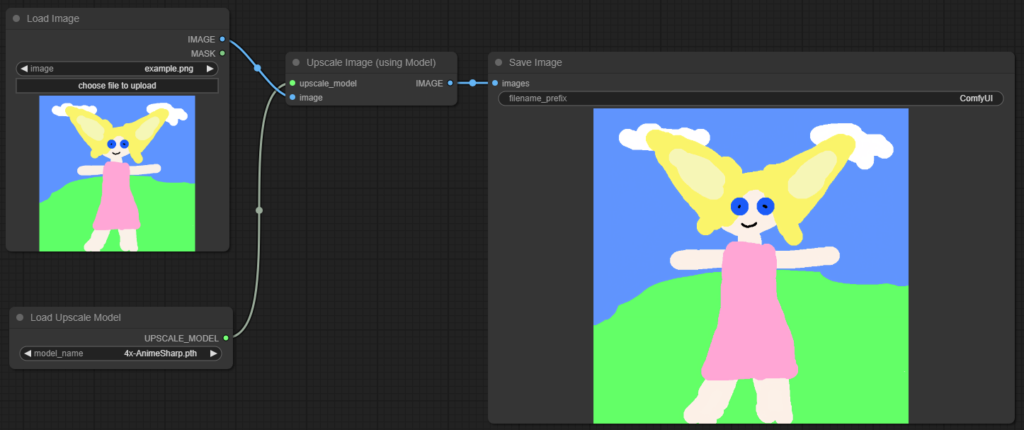
Links kann man ein lokales Bild oben auswählen und im unteren Kasten das zu verwendende Modell für die Hochrechnung. Rechts ist dann das hochskalierte Bild nach der Ausführung zu sehen. Es stehen verschiedene Modelle für das Upscaling zur Verfügung, die auch meist frei verfügbar sind (z.B. relativ bekannt/verbreitet ESRGAN, AnimeSharp,…)
Das nur mal als kleines optisches ComfyUI Beispiel.
Wir hatten in der Tat vor einigen Jahren mal die Diskussion für Jadice Flow, ob wir dort auch feingranulare Elemente, ähnlich wie in der comfyui, haben wollen. In Flow sind dies quasi die Ablaufschritte. Diese haben bei Flow eine einheitliche Ein/Ausgangsschnittstelle, in comfyui ist man da eher mit den einzelnen Parametern unterwegs. Aber Details…
Kern-Knoten für Verarbeitung von SD Modellen in ComfyUI ist der “KSampler” (im folgenden Bild im blauen “First Pass” Bereich). Diesem Knoten werden die Prompt-Eingaben für die Erzeugung übergeben. Parameter sind jeweils auch Knoten und werden mit dem Sampler verbunden. Dieser liefert dann einen Output, den man als Bild ausgeben oder weiterverarbeiten kann.
Es können auch eigene Knoten in Python implementiert werden. Dazu gibt es eine Art App-Manager, um diese Knoten relativ komfortabel direkt installieren zu können. Einige Custom Nodes sind hierbei bereits verfügbar. Meist im Bereich der Stable Diffusion-Verarbeitung, aber zunehmend kommen u. A. durch die Community auch andere Knoten wie z. B. eine Ollama-Anbindung dazu, um die Prompts für Stable Diffusion über Ollama bzw. ein anderes Sprachmodell generieren zu können.
Beispiel-Ablauf Bilderzeugung:
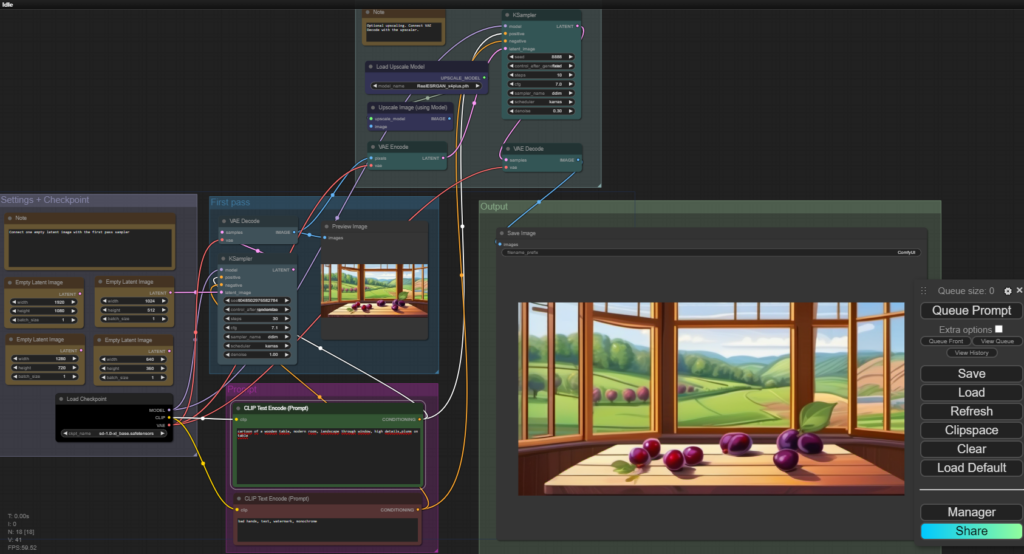
Man kann Knoten farblich gruppieren. Hier sieht man grob:
- Links in lila: Einstellungen: Bildgröße + Modell
- First Pass (blau): Erhält die Prompts aus dem magenta Bereich und erstellt ein Bild
- Second Pass (oben): Upscaling
- Ergebnis dann rechts im Output
Die Comfyui Workflows können nun beliebig komplexe Formen annehmen. Üblicherweise gibt es mehrere Läufe / Passes, um z.B. Details zu ergänzen oder ein Upscaling durchzuführen.
Hier mal beispielhaft ein Workflow mit Bilderzeugung, einem sogenannten Refining (Anreicherung von visuellen Details) und anschließendem Upscaling auf 4k:
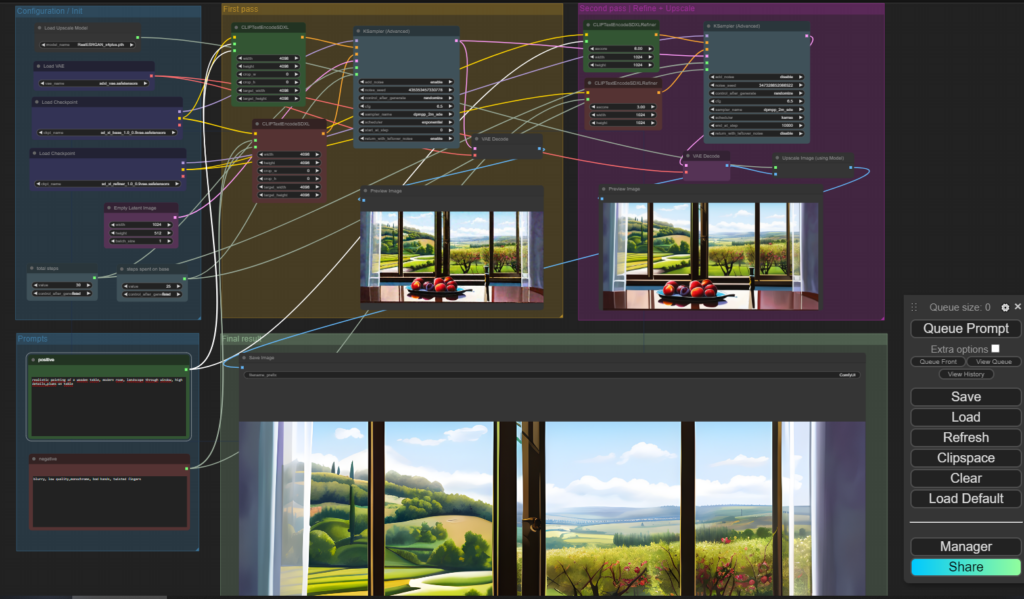
Prompt:
realistic painting of a wooden table, modern room, landscape through window, high detail, plums on table

Comfyui und jadice flow
Eine Möglichkeit zur Überschneidung mit unserer Jadice Welt könnte z.B. sein, dass in einem Custom-Node für die Comfyui eine Anbindung an Jadice flow implementiert wird. Es wäre dann möglich, einen Jadice-Flow Node in Comfyui zu konfigurieren und damit Bilder aus Comfyui an Flow zu übergeben für weitere Verarbeitung (oder auch andersrum aus Flow Dokumente in den Comfyui Workflow übergeben).
Ein Anwendungsfall könnte z.B. Anonymisierung von Bildern sein, indem Personen oder Objekte kaschiert werden (z.B. bei Immobilien-Fotos, um “unerwünschte” Personen zu entfernen).
Aktuell gibt es zu solchen Vorhaben aber noch keine genaue Planung in Jadice Flow, wäre als Experiment aber durchaus interessant.
Morph Animationen mit AnimateDiff
In einem Experiment wollte ich nun also (endlich) eine Animation erstellen. Aber wie geht man hier vor?
Man könnte nun viele Einzelbilder generieren und diese einfach aneinanderreihen.
Dies führt aber nicht zu einer “sanften” bzw realistischen Animation, da die Bilder untereinander dann doch zu viele Unterschiede aufweisen können.
Es wird noch eine Transition benötigt, also ein sanfterer Übergang zwischen den Bildern.
Da gibt es nun verschiedene Optionen. In diesem Beispiel wird das Modul “AnimateDiff” in comfyui genutzt. Dort werden Modelle verwendet, welche darauf spezialisiert sind, Bewegungen zu erkennen und Übergänge zwischen Bildern zu erzeugen. Hierbei werden Schlüsselelemente im Bild erkannt und stellenweise über einige Bilder hinweg länger beibehalten, ebenso werden “Kamerabewegungen” möglich. Dadurch entstehen interessante Morph-Effekte.
Der Workflow ist mittlerweile auf diesen Stand angewachsen:
Das ist nur ein Überflug-Bild ohne Details. Man sieht aber schon, dass etwas mehr Schritte erforderlich sind.
Wir wissen ja jetzt bereits, wie man Einzel-Bilder erzeugt, aber wie ist das nun mit unserem “Drehbuch” für die Animation? Alles von Hand manuell erzeugen?
Prompt Travelling
Zum Glück gibt es hierzu bereits eine Lösung, das sog. “Prompt Travelling”. Hierbei werden mehrere Prompts mit einer Keyframe-Angabe auf einmal eingegeben.
Man schreibt somit eine Art Drehbuch auf Basis von Schlüsselbildern. Die Animation bzw. Übergänge zwischen diesen Schlüsselbildern kommen durch die AnimateDiff-Magie hinzu.
Für die Beispielanimation habe ich mal dieses einfache Beispiel mit “Obst auf einem Tisch” verwendet:
Genereller Prompt (gültig für alle Key-Frames):
cartoon of a wooden table, modern room, landscape through window, high details,
Und nun die speziellen Prompts für die Animation:
"0": "apples on table,",
"30": "oranges on table,",
"60": "bananas on table,",
"90": "ananas on table,night",
"120": "raspberry on table,sunset,",
"150": "plums on table,",
"180": "strawberries on table,"
Die Zahl gibt hierbei wie erwähnt die Frame/Bildnummer innerhalb der Animation an. In diesem Fall wird die Animation später mit 8 Bildern pro Sekunde berechnet. Kombiniert mit der Länge von 210 Frames ist die Animation also ~26sec lang.
Im obigen Beispiel sieht das im Detail dann also so aus:
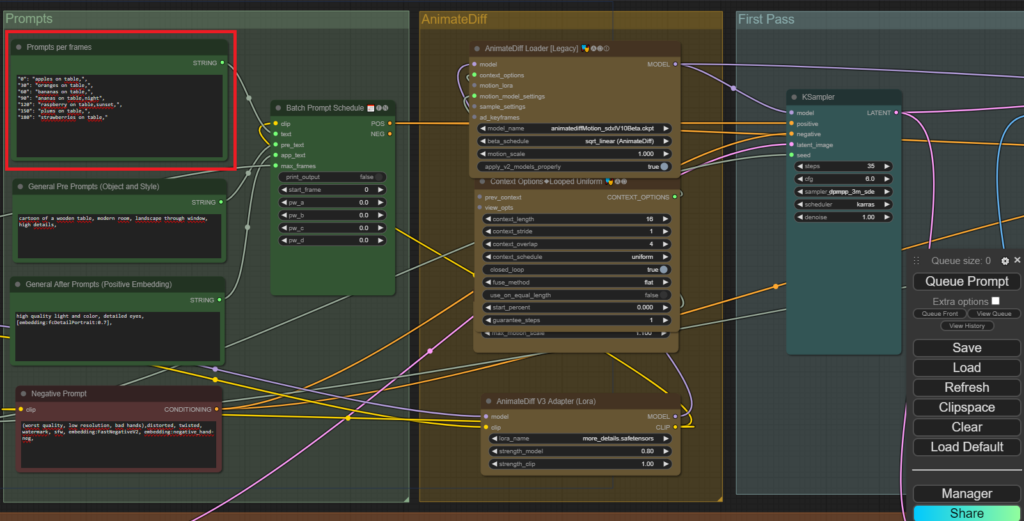
Nun wird also aus den Prompts ein Zeitplan erstellt und Bilder generiert. AnimateDiff hat ein eigenes Bewegungs-Modell und errechnet nun Zwischenbilder für die Animation.
Das Ergebnis sieht dann am Ende so aus (640×360 pixel, 8 FPS, 3.9mb):
Die Renderzeit betrug ca. 15min. Ich persönlich finde ja solche Morph-Animationen fantastisch. Auch interessant, wenn Personen auf dem Bild sind, die laufen dann umher, aber solche Beispiele wollte ich hier mal lieber außen vor lassen.
Und natürlich sind hier dann auch Workflows möglich, um unter Umständen rechtlich bzw. moralisch fragwürdige Dinge zu tun, wie Gesichter auszutauschen, Personen verschwinden oder erscheinen zu lassen etc.
Audio-Erzeugung
Kommen wir mal noch zu einem weiteren Bereich, mit dem ich mich kürzlich beschäftigt habe. Ich mache hobby-mäßig schon länger Sachen mit Musik, so bin ich dann auch zuletzt auf einige Tools für GenAI im Audio Bereich gestolpert.
GenAI im Musikbereich
Hier sind zuletzt einige Anbieter wie Suno.ai und Udio aufgefallen, bei welchen die Ergebnisse zur Musikerzeugung bereits einen interessanten Stand erreicht haben. Bei diesen Anbietern kann man einen Text im Browser eingeben und erhält ein paar Minuten später ein fertiges Lied.
Die erstellten Songs haben stellenweise eine beeindruckende Qualität was Sprachsynthese und Komposition angeht, aber noch ist insgesamt die Tonqualität mit einer relativ hohen Audio-Kompression behaftet; je nach Musikstil etc.
Bei Suno.ai können z.B. aktuell 4min lange Songs erstellt werden, indem man den Songtext übergibt oder auch komplett generieren lässt. Ebenso können gewisse Steuerungsbefehle übergeben werden, die das Modell dann verwendet z.B. [solo], [instrumental], [verse], [intro], [outro]
Dort hatte ich einige Experimente durchgeführt, verweise an dieser Stelle aber auf die dort jeweils öffentlich verfügbaren Songs als Beispiel. Siehe auch https://suno.com/.
Audio-Erzeugung (Sprache)
Suno hatte das Bark Modell (https://github.com/suno-ai/bark) bereits vor einigen Monaten Open Sourced, damit kann man sehr einfach Text zu Audio lokal generieren. Die Ergebnisse sind hierbei schwankend gut, aber es sind auch einige “Effekte” wie Lachen und Hintergrundgeräusche etc. möglich.
Das Beispiel dort auf der GitHub Seite kann von Interessierten quasi direkt z.B. in einem Python Notebook ausprobiert werden (oder das dort liegende Beispiel angehört werden).
Dieses Modell ist vermutlich auch die Grundlage für das Suno.ai Musikmodell gewesen – dort ist es mMn aber noch deutlich ausgefeilter.
MIDI-Erzeugung
Auch wenn die Ergebnisse von Suno.ai & Co. extrem verblüffend sind, ist doch die Audio Qualität meist noch nicht 100% top. Stellenweise will man auch einfach nur eine Kleinigkeit der Melodie ändern, was aber nicht so einfach geht (außer Teile oder alles neu generieren).
Eine Option für Musiker ist hierbei auch die direkte Integration von KI-Tools in die jeweiligen bekannten Musikprogramme wie z.B. das in Apple bekannte Logic Pro oder Ableton Live, Reason und dergleichen.
Persönlich empfehle ich natürlich immer Ableton; dort in Berlin habe ich auch mal vor über 20 Jahren ein Mini Praktikum gemacht :-)
Google ist hier ebenfalls unterwegs mit dem unter OpenSource Lizenz stehenden Magenta Studio. Man benötigt für die aktuelle Version 2.0 Ableton Live, da das dort direkt als Plugin integriert ist.
Die Version 1.0 ist aber auch noch als Standalone Programm frei verfügbar (siehe voriger Link für Download). Das Magenta Studio beinhaltet mehrere separate Tools, z.B. “Continue”. Mit diesem Tool lassen sich zu einer MIDI Melodie dann weitere Noten generieren.
Die Verwendung ist denkbar einfach. MIDI Datei einfügen, generieren drücken:
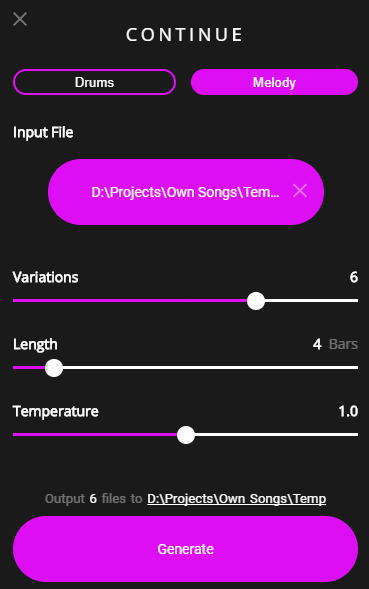
Hier als Beispiel der erste Takt aus “Alle meine Entchen” – hierzu sollen dann 6 Variationen bzw. Fortführungen der Melodie generiert werden.
Die Ergebnisse hierbei sind aber eher als experimentell zu betrachten. Für die Musik-Software-Verwendung z.B. innerhalb Ableton Live ist das ok, aber als Standalone Applikation ist dies in der Tat dann nicht mehr so sinnvoll, da die Ausgabe auch meist noch nachbearbeitet werden muss.
Beispiele
Habe die MIDI Dateien hier schon zu MP3 konvertiert, damit sie im Browser verwendet werden können.
Original:
Continue:
Continue mit Suno
Auch Suno bietet mittlerweile die Möglichkeit, eine Audiodatei hochzuladen. Es kann dann die “Continue”-Funktion genutzt werden, um den Song zu erweitern. Man kann somit Instrumente oder generelle Art der Musik besser vorgeben.
Hier mal nur ein ganz kleines Beispiel mit etwas Percussion (von mir erstellt mit Reason):
Original:
Via Suno erweitert:
Vermutlich ist das Ausgangsmaterial nicht ganz ideal… ![]() Aber man kann schon erkennen, dass Teile der Original-Percussion beibehalten werden. Interessant ist das natürlich auch mit Melodien und Sprache, aber das kann ja jeder selbst mal ausprobieren – Suno kann ja umsonst verwendet werden (für nicht kommerzielle Nutzung). Ich hatte hier aber wie bereits erwähnt einen Pro-Account verwendet.
Aber man kann schon erkennen, dass Teile der Original-Percussion beibehalten werden. Interessant ist das natürlich auch mit Melodien und Sprache, aber das kann ja jeder selbst mal ausprobieren – Suno kann ja umsonst verwendet werden (für nicht kommerzielle Nutzung). Ich hatte hier aber wie bereits erwähnt einen Pro-Account verwendet.
Fazit / Wie geht es weiter?
Nach diesem Ausflug in die “mediale Welt” wird es das nächste Mal möglicherweise um eines der folgenden, näher an Flow liegende Themen gehen. Die haben es hier umfangmäßig nicht mehr rein geschafft:
- Experimente mit Vektor Datenbanken – evtl. nicht nur für LLMs interessant, sondern auch als Such-Index…
- FunctionCalling in LLMs – Modelle rufen Funktionen auf, die man als @Bean in der SpringBootApplication registriert hat. Geht seit 4 Wochen auch lokal mit Ollama und dem neuen Mistral 0.3 Modell – sehr spannend :-)
- Jadice Flow Themen, z.B. könnten wir mal einen Blick in das Monitoring unserer Testumgebung werfen und die predictive Analyse für System-Auslastung oder weitere Dinge des Betriebs anschauen
- Und natürlich noch vieles mehr, also: stay tuned
Ich danke für die Aufmerksamkeit.
Damit sind jetzt erstmal alle wieder im (generierten) Bilde – bis zum nächsten Mal :-)