

Mit dem jadice viewer, dem webtoolkit und der E-Akte lassen sich unter anderem PDFs anzeigen, mit jadice server und jadice flow werden PDFs verarbeitet. Das PDF-Format erfreut sich großer Beliebtheit, sodass mit unseren Produkten täglich große Mengen PDFs verarbeitet werden. Dies spiegelt sich auch darin wider, dass das PDF ein Format ist, zu dem es im Support häufiger Anfragen gibt.
Nachstellen des Problems
Erfolgt beispielsweise die Meldung, dass ein PDF nicht wie erwartet angezeigt wird, versuchen wir im ersten Schritt, die vom Kunden gemeldete Problematik bei dem PDF-Dokument nachzustellen. Zunächst werden, sofern vorhanden, Fehlerausgaben aus dem Log vom Kunden gesichtet. Dann wird das Dokument im viewer (in der BasicDemo) geöffnet, um zu prüfen, ob das Problem nachgestellt werden kann bzw. welche Logmeldungen auftreten. Gegebenenfalls muss eine alte Version des viewers in der IDE (Entwicklungsumgebung) ausgecheckt werden, um damit zu versuchen, den Fehler zu reproduzieren, weil das Problem in der aktuellen Version bereits behoben ist.

Analysetools
Zur Analyse von PDF-Dokumenten werden sowohl auf dem Markt erhältliche Tools als auch interne Expertenwerkzeuge eingesetzt werden. Bei Bedarf können beispielsweise mit Analysetools Bilder oder Fonts aus dem Dokument extrahiert werden, um sie isoliert zu betrachten.
Aufbau des PDFs
Mit dem von levigo erstellten und intern genutzten Tool docinspector kann der/die MitarbeiterIn die PDF-Objekte ansehen. Alternativ kann das Dokument mittels eines Tools dekomprimiert werden, sodass die Streams, die PDF-Objekte enthalten, für Menschen lesbar werden. Dann kann man das Dokument in einem Texteditor nach Objekten bzw. Syntax, die ungewöhnlich erscheinen oder selten auftreten, durchschauen.
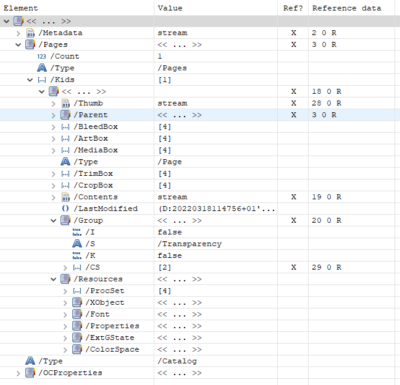
Es kommen weitere Dokumentenanalyse-Tools zum Einsatz, die Angaben zur Korrektheit/Fehlern im Aufbau des Dokuments machen: Stimmt die Struktur der PDF-Objekte? In den Streams wird untersucht, ob die Schachtelung der Operatoren stimmt, die jeweils ein öffnendes und ein schließendes Element haben müssen. Sind die Fonts in Ordnung?
Renderingstruktur anzeigen
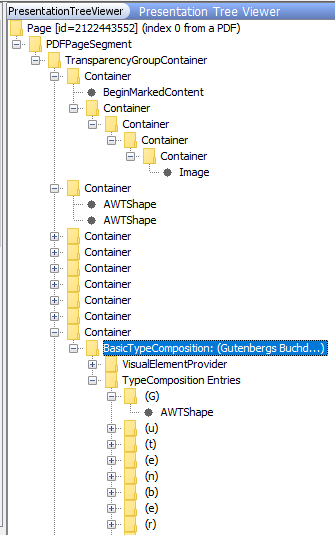
Aus den eingelesenen PDF-Objekten wird im Programmablauf des viewers ein Baum, der die Renderingstruktur abbildet. Diese gibt an, welche Objekte in welcher Reihenfolge und mit welcher Transparenz an welcher Stelle der Seite abgebildet werden. Diese Renderingstruktur können Mitarbeitende mit dem Debug-Panel anzeigen lassen.
PDF-Spezifikation
In der ca. 1000-seitigen englischen PDF-Spezifikation ist der Aufbau von PDF-Dokumenten festgelegt. Diese verweist auf weitere Spezifikationen, z. B. für einen bestimmten Font-Typ. Häufig muss im Support geprüft werden, ob ein PDF-Dokument der PDF-Spezifikation entspricht.
Vereinzelt gibt es offene Fragen, die die Spezifikation nicht festlegt, hier können andere Viewer herangezogen werden, um deren Verhalten zu prüfen, damit das Dokument in verschiedenen Viewern gleich angezeigt wird.
Erstellen eines PDFs mit dem Fehler
Manchmal ist es nötig, im Hex-Editor Elemente aus dem PDF zu löschen, um die Ursache des Problems einzugrenzen.
In vielen Fällen muss ein neues PDF mittels eines von levigo erstellten PDF-Generators erzeugt werden, das nur isoliert dieses Problem enthält. Mit dem PDF-Generator können PDF-Objekte eingefügt und bearbeitet werden, um dann daraus ein neues Dokument zu erstellen.
Die mittel PDF-Generator neu erstellten Dokumente können sowohl zur Analyse als auch für interne Regressiontests verwendet werden, falls JUnit-Tests nicht ausreichend sind. Die Regressiontests verhindern, dass durch neue Codeänderungen das Rendering oder die Textextraktion bestehender Dokumente verändert wird.
Debuggen in der IDE
Aufgrund der Sichtung der Logausgaben kann in relevanten Klassen ein Breakpoint gesetzt werden und der Programmcode bezüglich des Verhaltens für dieses Dokument debuggt werden. Bei Problemen, die vermutlich durch kleinere Änderungen lösbar sind, können kleinere Codeänderungen sofort ausprobiert werden. So kann überprüft werden, ob an der angenommenen Stelle tatsächlich die Ursache des Problems liegt. Wenn umfangreichere Codeänderungen nötig sind, wird für die Thematik ein Produktticket angelegt und eingeplant.